How is a data lake different from a database and why do analysts need one?
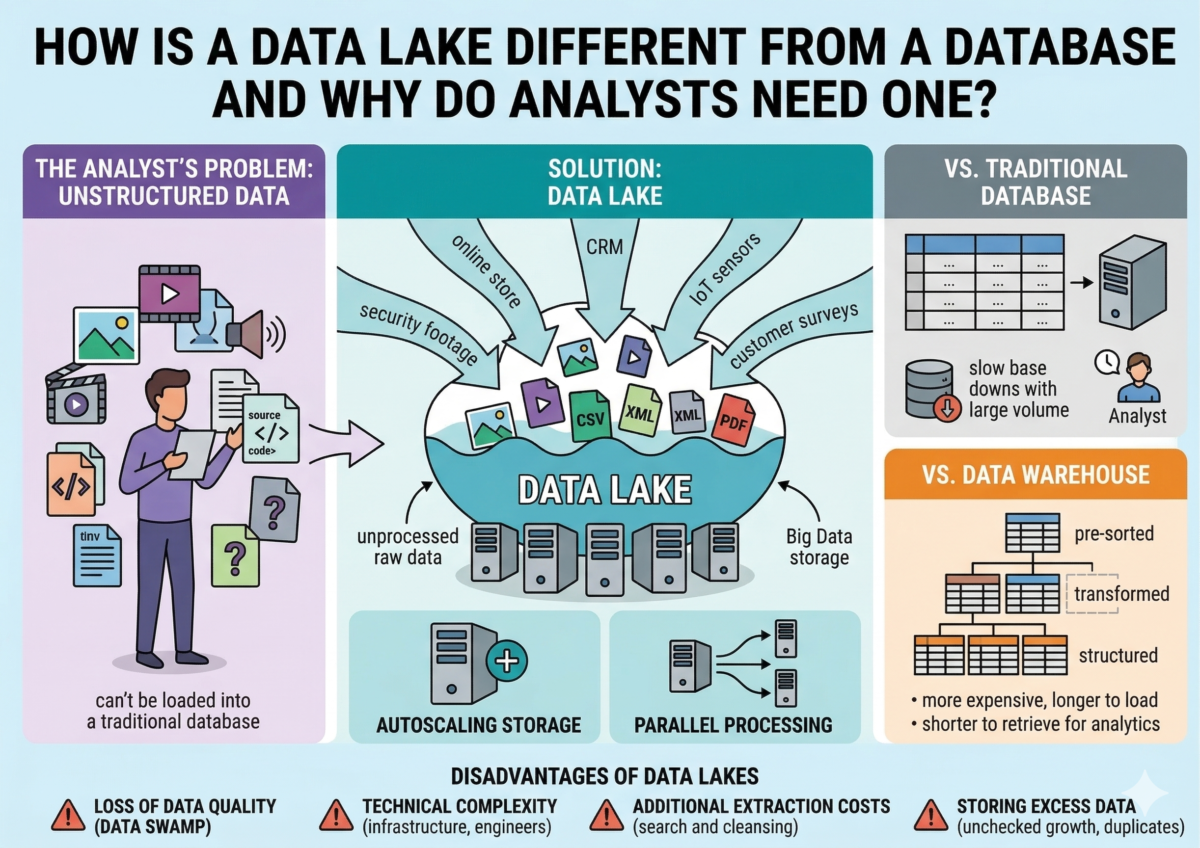
Table of Contents
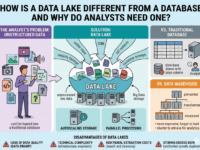
What is a Data Lake?
Let’s imagine a company with a wealth of data from various sources: an online store website, cash registers, customer surveys, CRM systems, and security camera footage from the sales floor. All this data needs to be stored somewhere for analysis.
A simple database would not be the best choice for this for two reasons:
● It is not designed to handle large amounts of regularly incoming data. As the load increases, the database will begin to read and write information more slowly and will not be able to expand evenly or autoscale if the data volume becomes too large.
● A database is often needed for the normal operation of core business systems, such as a website. If it is also accessed for analytics, it can become overloaded, causing the website to slow down or even crash. Therefore, the database for business and analytics should be separated.
There are two possible solutions for this: a data warehouse and a data lake. A data warehouse is essentially a database that can store structured information. Data is stored in tables and must be processed and structured before loading.
Scattered, unstructured data of various formats cannot be stored in a data warehouse. To solve this problem, a Data Lake was invented. This tool allows you to store any type of data: CSV, XML, JSON, Parquet, JPG, PNG, MOV, MP3, PDF, and more. It can accommodate tables that lack a clear structure, meaning the number and names of columns and rows change periodically. All this data can be loaded into the lake without any processing, meaning it’s practically instantaneous.
Who needs data lakes and why?
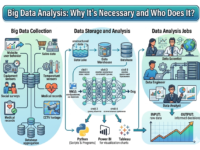
Data lakes are designed to collect, store, and process large amounts of information arriving in a virtually continuous stream. This information is called Big Data.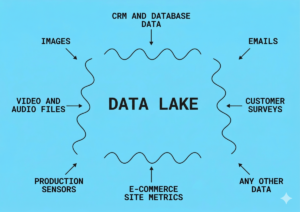
Data lakes are useful for all companies planning to analyze big data across fields such as retail, IT, manufacturing, and logistics.
A data lake on its own is useless because it’s just a repository. Working with it requires tools to clean, structure, extract, and analyze the data, as well as specialists to operate these tools.
You can do without a Data Lake if the company:
● Does not work with Big Data at all and has no plans to do so in the near future. This is typical for small businesses with minimal IT infrastructure and a small volume of incoming data.
● Primarily collects structured data, for example, from databases or metrics collection systems. In this case, it can be immediately placed into storage and used for analytics.
How a data lake works
A data lake is a file storage solution across multiple servers that stores data. Typically, the data is distributed across servers so that the storage can be quickly scaled by adding new servers to expand the storage space.
Connections to various data sources available to the company are configured to the servers. Data delivery channels are called pipelines, and the entire connection scheme is called an ETL process. Typically, everything is configured so that data is loaded automatically.
Although a data lake is unstructured, it still needs to be organized; otherwise, over time, a huge amount of data will accumulate that will be impossible to understand. Therefore, before adding data to the lake, it’s tagged, and its origin and format are recorded.
As a result, the data lake stores not only the objects themselves but also metadata, or information about the objects. This facilitates future search, retrieval, and analysis of the data.
The data lake architecture must include backup tools to ensure that information is not lost.
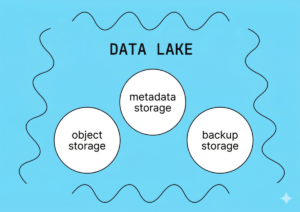
A data lake doesn’t exist in isolation. Other tools complement it:
● Sources from which data is generated and collected. These may include databases, CRM, ERP, IoT, and other systems and services.
● Analytical services that select, sort, and analyze information. For example, these are BI tools for building dashboards. Or machine learning services for creating ML models and neural networks.
● Warehouses that already contain structured and cleaned data from the lake.
Data analysts interact with tools rather than the data lake directly. Modern data lakes are typically built using Hadoop. It allows incoming data to be stored on different subservers and processed in parallel, significantly speeding up workflows.
How Data Lakes Work
- Data is generated in one source. For example, on a social network, users send each other messages containing text, images, videos, and voice messages.
- Data from the social network’s servers is sent to the Data Lake via a pre-configured route.
- When data is received, it is marked up: its source, time of receipt, format, and structure are recorded.
- Data is placed in a data lake and stored there. Typically, the data is retained indefinitely, although sometimes it is deleted as it becomes outdated or is used for analytics.
- If necessary, data is extracted from the warehouse according to specific criteria and used in analytics and machine learning.
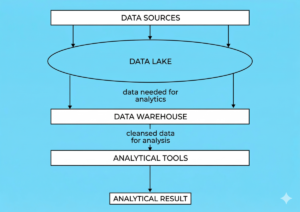
Data lakes and data warehouses
Data warehouses and data lakes are used to work with large volumes of data. Let’s explore the differences between data warehouses and data lakes.
Data lake. Designed for storing any type of data. Before analytics, it must be found, cleaned, and structured. This means that placing it in a data lake is easy, but retrieving it is more difficult. Due to its lack of structure and ease of maintenance, a data lake is less expensive than a data warehouse.
Data Warehouse.
Built on distributed databases—both classic and specialized ones, like ClickHouse. It contains pre-sorted, transformed, and structured information. Data from the warehouse can be immediately used for analysis. Placing information in the warehouse takes longer because it must be structured first. Because of its structure, data in the warehouse takes up more space and requires more complex maintenance, making the warehouse itself more expensive than a data lake.
There are hybrid warehouses where all unstructured data is first placed into a lake, and then taken from there, cleaned, structured, and loaded into the warehouse.
Disadvantages of data lakes
Loss of data quality. A data lake tends to become a “swamp,” accumulating poorly labeled and unneeded data. This can lead to the data lake simply becoming unusable for analytics—it will have to be completely erased and repopulated, more carefully.
Technical complexity. Creating a data lake is a complex task. It requires infrastructure: powerful servers, reliable communication channels, large amounts of disk space, and experienced engineers to support it. Data lake technology is relatively new in some countries, and there are not many specialists on the market, so finding them will require a long search and high costs.
Additional data extraction costs. While data can be placed into a lake almost instantly, extraction often requires complex search and cleansing tools that must be configured separately. In this regard, a data lake is inferior to a data warehouse, where everything is stored according to a pre-defined structure.
Storing excess data. Data often flows into the data lake unchecked. This can lead to numerous duplicates and files that are completely unnecessary for any analytics. This can cause the data lake to grow and consume too many business resources.
Expert advice
Moses Gaspar
A data lake is a relatively reliable and affordable way to store data. To use it, a company needs to develop quality control, delivery processes, and a data management policy. This is called a data culture, and without it, a data lake will be of no use. Therefore, building and populating a data lake requires a comprehensive approach, collaborating with various specialists and utilizing modern approaches and technologies.