How ETL processes help analyze big data
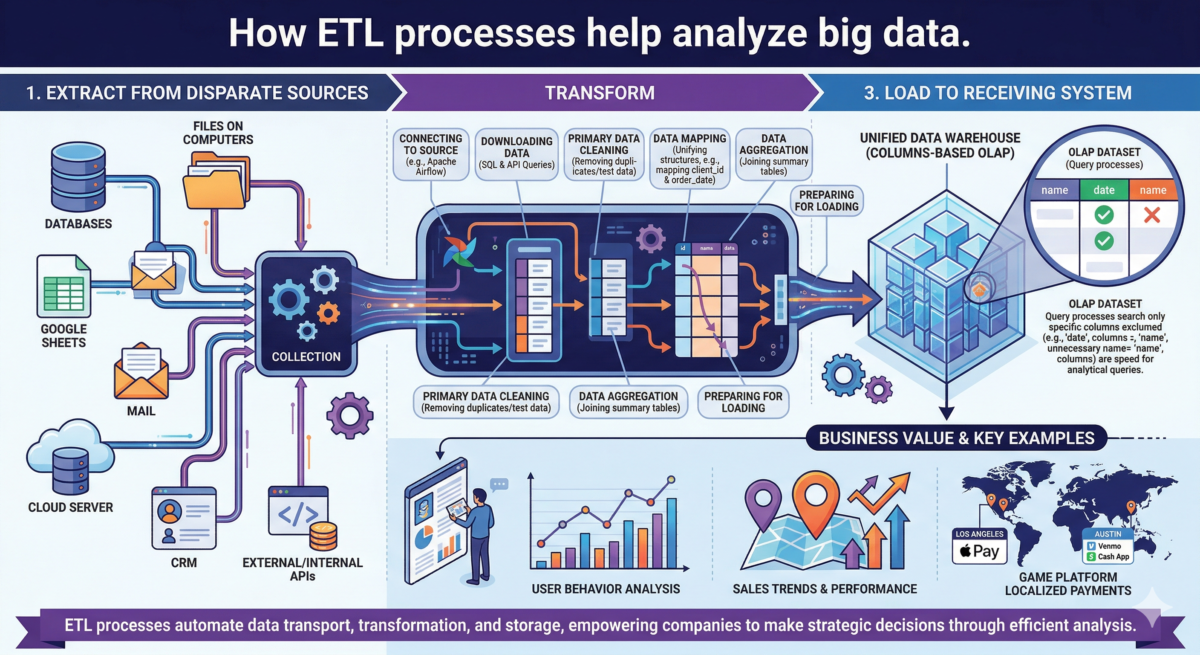
Table of Contents
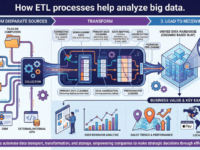
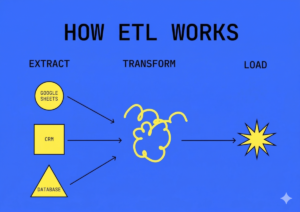
ETL is a data transport process that transforms information from different locations and places it in a new location. ETL stands for extract, transform, and load.
Typically, company data is stored in different places:
● files on work computers;
● Google Sheets;
● mail;
● cloud server;
● databases;
● copies of databases used for reporting;
● CRM (customer relationship management system);
● external and internal APIs.
Each source has its own method for providing access to data: databases require direct connections, files require links, and APIs require an authorization token. These methods are often not readily available for quick use, making it difficult to compare data from different sources. To make data easy to work with, it needs to be given a unified structure, stripped of unnecessary elements, and stored in a data warehouse. This is what the ETL process is for.
ETL processes help companies implement useful features and make strategic decisions. In the “Data Engineer from Scratch” course, students learn to use ETL tools and implement processes.
Who and where uses ETL
ETL processes are used by analysts and data engineers in IT companies that face one of two problems:
● There is too much data, so analytical queries take a long time to run, and you have to pay for storing excess data.
● The data is located in different places, so analysts cannot work with it.
Let’s consider both cases in detail.
Too Much Data
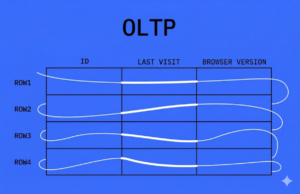
Let’s say the company “Alfa” stores information in an OLTP (Online Transaction Processing) database. It’s designed for fast writing and reading of a single unit of data—a row.
When analysts work with company data, they query this database. For example, to find out how many users visited the Alfa website yesterday, they need to iterate through all the rows in the database for that day. The more users there are, the more computing power is required to iterate through all the rows. At some point, problems arise: queries take a long time to process or fail due to database limitations—the database simply returns an error in response to the query.

Calculating the number of visitors, the average check, or the median age are all analytical functions. ETL is used to move the data into a database designed for analytical processes.
The data is stored in different places.
Customer data frequently resides in disparate systems, scattered across various platforms. Consider Anton’s journey: back in 2007, he established a Gmail account, creating a username, providing his date of birth, and indicating his gender. This foundational personal information was securely stored within a dedicated database managed by Google’s development team.
Fifteen years later, in 2022, Anton decided to pivot into data analytics. He enrolled in an introductory course on Coursera, conveniently logging in using his existing Google account. As Anton made progress through the curriculum, details about his course completion and engagement were saved in a separate database maintained by Coursera.
Later, a marketing specialist at Coursera approached an analyst with a critical business question: “How does the age of our students influence their completion rates for trial courses?” The analyst faced an immediate challenge. Anton’s age data was housed in Google’s system, dating back to 2007, while his course completion data resided in Coursera’s distinct database. To bridge this information gap, the analyst undertook the task of integrating data from these separate systems, consolidating it into a centralized analytical data warehouse. Now, Coursera’s student profiles are unified in a single location, enabling comprehensive and efficient analysis.
Here are a few more examples of tasks where ETL helps combine data from different sources:
Analysts at a food delivery service want to understand how personalized product recommendations impact sales. The recommendations are one database, and the shopping cart is another. To compare data from the two systems, they set up an ETL process.
The bank issues loans. One system stores information about money transfers, and another system stores loan application status. ETL links loan payment data with application data. Analysts use this information to understand which application factors influence loan fulfillment.
To provide a more seamless checkout experience, payment platform developers are streamlining how they prioritize payment methods for gamers. By integrating disparate datasets—specifically game genres and regional transaction trends—through an automated ETL (Extract, Transform, Load) pipeline, the system can deliver hyper-localized payment options in real-time. For example, the platform could automatically prioritize Apple Pay for League of Legends players in Los Angeles, while instantly suggesting Venmo or Cash App to Call of Duty fans in Austin.
Advantages and Disadvantages of ETL
How does the ETL process work?
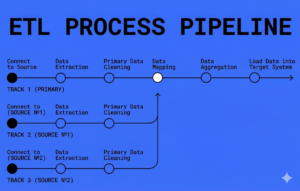
1. Connecting to the source
2. Downloading data from the source
If the source is a database, an SQL query is sent to retrieve the information —a set of commands for working with table databases. If data needs to be retrieved from an external source, such as a CRM, files, or email, an API is used, which allows different applications to exchange data with each other.
At this stage, it is important to consider the volume of data being downloaded: if the system receiving the data does not have enough memory, the processes will run with errors.
3. Primary data cleaning
4. Data mapping
-
Data aggregation
Aggregation is the joining of data into a summary table. For example, let’s say we need to find out the average number of orders placed by customers of different ages.
Table with orders:
|
order_id
|
client_id
|
order_date
|
|---|---|---|
|
1
|
4
|
2021-10-01
|
|
2
|
6
|
2021-10-02
|
|
client_id
|
client
|
age
|
|---|---|---|
|
4
|
Mark
|
23
|
|
6
|
Inna
|
35
|
|
age
|
orders
|
count
|
|---|---|---|
|
23
|
13
|
|
|
35
|
15
|
|
- Loading data into the receiving system
How to implement an ETL process
To set up an ETL process, an analyst needs to complete five steps:
1. Understand the task.
For example, a company is developing a bonus system for salespeople. This requires analyzing data on sales volumes and bonuses. A data engineer is tasked with setting up the process of collecting and delivering data to an analytical warehouse. To do this, the engineer must determine:
– What systems are used to store data: CRM, databases, and documents.
– What should the receiving table look like, in which the final information will be saved: what should be the format and column names?
– How often does the information need to be updated: once a day, once an hour, or in real time?
– What information needs to be updated: only that which appeared within the set time, or that which was already in the database.
– What problems might arise in the data, and how to handle them. For example, gaps, anomalies, test values, and incorrect formats.
– How will the system notify the customer about any issues that arise? For example, if the system receives half as much data as usual one day.
After understanding the task, the engineer requests access to the data.
2. Gain access to data.
For example, sales data is stored in 1C, employee data is in Google Sheets, and bonuses are in a database. Systems have different access requirements and different authorities who can grant this access. To access the data, typically follow these steps:
– Contact those responsible and agree with them on access to systems and the necessary data.
– Create a separate account for the automated ETL process. This is necessary to control who retrieves this data.
– Create a personal data engineer account for quick data validation and debugging. Access is typically limited, for example, so the engineer doesn’t see clients’ personal data.
– Provides access to a test circuit—test data on which you can configure and test the ETL process.
3. Validate the received data.
At this stage, it’s necessary to determine which data is needed and which must be eliminated. For example, the tables may contain test sales accounts that shouldn’t be included. Or bonuses may be awarded in kopecks, but they should be stored in rubles in the data warehouse. The data engineer receives some of the information, analyzes it, and, if it determines that the data needs to be preprocessed, takes this into account when writing the code. This part of the processing is also called “data preprocessing.”
4. Write the ETL process code.
Once it’s clear what data is needed, where to get it, and how to process it, the data engineer writes the code, which then becomes the ETL pipeline—that’s what analysts call the ETL process. While writing the code, it’s tested:
– The code technically works properly and does not generate any errors during execution.
– The code is written in a readable manner: parameter names, line breaks and tabs, and text formatting rules are correct.
– The data is processed correctly, and there are no calculation errors after processing.
All that remains is to automate the entire ETL solution and hand it over to customers.
5. Run automated code execution.
To avoid manually running the ETL process each time, there are specialized tools, such as Apache Airflow or PySpark. These frameworks execute prepared code, and task execution can be monitored in the interface and logs.
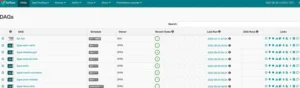
An ETL pipeline can be described as a set of sequentially executed tasks, using the example of a batch process in Apache Airflow. A batch process means that data is taken in chunks and the process is run on a schedule.

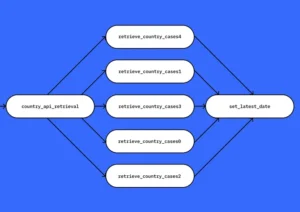
Examples of ETL systems
One of the most popular systems for managing ETL processes. Runs tasks:
– by trigger,
– according to the schedule,
– by sensor.
There’s an interface for process auditing and solution monitoring. It allows you to run tens or even thousands of ETL processes simultaneously, for example, to collect sales statistics for franchise restaurants in different cities.