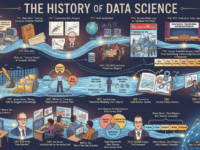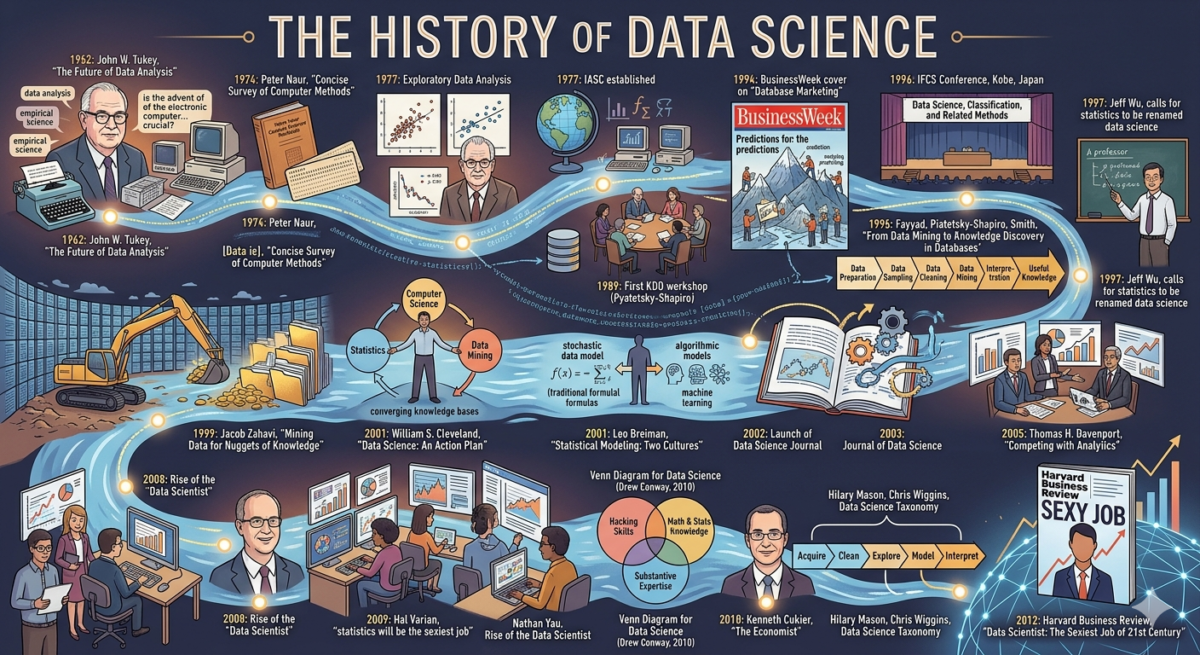
Data science is one of the most in-demand professions in IT. It continues to gain momentum, although it only emerged as a distinct discipline relatively recently. This Saturday, we’re sharing a comprehensive, comprehensive resource that will help you learn or revisit the key stages of developing the profession.
Making sense of data has a long history and has been discussed by scientists, statisticians, librarians, computer scientists, and other professionals for many years. Let’s explore the evolution of the term “data science,” its usage, attempts to define it, and related terms.
The term “Data Science” has emerged quite recently [the original English article was published by Forbes in 2013] to describe a new profession that must make sense of vast repositories of big data.
1962. In his article “The Future of Data Analysis,” John W. Tukey writes:
“For a long time, I considered myself a statistician, interested in drawing conclusions from the particular to the general. But as I observed the development of mathematical statistics, I began to have questions and doubts <…> I came to the conclusion that my main interest lay in data analysis <…>
Data analysis and those sections of statistics which adhere to it must… acquire the characteristics of a [separate] science, and not of mathematics <…> Data analysis is essentially an empirical science <…> How vital and how significant… is the advent of the electronic computer with stored programs?
In many cases, the answer may be surprising: “important but not vital ,” although in other cases there is no doubt that the computer was “vital.”
In 1947, Tukey introduced the term “bit,” which Claude Shannon used in his 1948 paper, “A Mathematical Theory of Communication.”
In 1977, Tukey published Exploratory Data Analysis, arguing that more emphasis was needed on using data to generate hypotheses for testing, and that exploratory data analysis and confirmatory data analysis “can and should work side by side.”

1974: Peter Naur publishes “Concise Survey of Computer Methods” in Sweden and the United States.
The book provides an overview of modern data processing methods used in a wide range of applications. The text is structured around the concept of data as defined by the International Federation for Information Processing ( IFIP ) in its Guide to Definitions and Concepts in Data Processing:
“[Data is] a representation of facts or ideas in a formalized form capable of being communicated or manipulated by some process.”
The book’s preface informs the reader that a course plan entitled “Data Science, the Science of Data and Data Processes, Its Place in Education” was presented at the 1968 IFIP congress, and that the term “data science” is used loosely.
Naur offers the following definition of data science: “The science of working with data once it has been established, while the connection of data with what it represents is delegated to other fields and sciences.”

1977 : The International Association for Statistical Computing ( IASC ) was established as a department of the International Statistical Institute ( ISI ) .
“The mission of the IASC is to combine traditional statistical methodology, modern computer technology, and the knowledge of subject matter experts to transform data into information and knowledge.”

In 1989, Grigory Pyatetsky-Shapiro organized and chaired the first workshop on knowledge discovery in databases (KDD). In 1995, the workshop became the annual ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
September 1994: BusinessWeek publishes a cover story on “Database Marketing” :
“Companies collect mountains of information about you, process it to predict how likely you are to buy a product. Then they use this knowledge to craft a marketing message precisely tailored to get you to do so <…>
The initial surge of enthusiasm sparked by the proliferation of barcode scanners in the 1980s ended in widespread disappointment: companies were too overwhelmed by the sheer volume of data to do anything useful with it <…> Nevertheless, many companies feel they have no choice but to boldly venture into the realms of database marketing.”
In 1996, members of the International Federation of Classification Societies ( IFCS ) gathered in Kobe, Japan, for their biennial conference. It was the first time the term “data science” was included in the conference title: “Data Science, Classification, and Related Methods.”
IFCS was founded in 1985 by six classification societies across countries and languages of classification, one of which, The Classification Society, was founded in 1964. Classification societies use the terms “data analysis,” “data mining,” and “data science” differently in their publications.

1996. Osama Fayyad, Grigory Piatetsky-Shapiro, and Padraic Smith publish the paper “From Data Mining to Knowledge Discovery in Databases.” They write:
“Historically, the concept of finding useful patterns in data has been given various names, including data mining, knowledge extraction, information discovery, information harvesting, data archaeology, and data pattern extraction <…>
In our view, KDD [knowledge discovery in databases] refers to the general process of discovering useful knowledge from data as a whole, and data mining refers to a specific stage of this process.
Data mining is the application of specific algorithms to extract patterns from data <…> additional steps in the KDD process such as data preparation, data sampling, data cleaning, incorporation of relevant prior knowledge and proper interpretation of the mining results are necessary to ensure that useful knowledge is extracted from the data.
Blindly applying data mining methods (rightly criticized in the statistical literature as data mining ) can be a dangerous exercise, easily leading to the discovery of meaningless and unhelpful patterns.”

1997: In his inaugural lecture for the Harry C. Carver Professorship, Jeff Wu (at the time of writing, at Georgia Tech) calls for statistics to be renamed data science and statisticians to be renamed data scientists.

1997: The journal Data Mining and Knowledge Discovery is launched; the reverse order of the two terms in the title reflects that “data mining” is becoming a more popular way of referring to “extracting information from large databases.”
December 1999. Jacob Zahavi is quoted in the article “Mining Data for Nuggets of Knowledge” in Knowledge@Wharton:
“Conventional statistical methods work well with small data sets. However, modern databases can contain millions of rows and dozens of columns <…>
Scalability is a huge challenge in data mining. Another technical challenge is developing models that can better analyze data, identifying nonlinear relationships and interactions between elements <…>
It may be necessary to develop specialized data mining tools to solve website-related problems.”
2001: William S. Cleveland publishes Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics.
This is a plan to “expand the core areas of technical work in statistics.” It is ambitious and involves significant changes, and the transformed field will be called “data science.”
Cleveland views the proposed new discipline in the context of computer science and contemporary work in data mining:
“…the benefits of data analytics have been limited because computer scientists have limited knowledge of how to think [in data analytics] and approach data analytics, as have statisticians’ knowledge of computing environments.
The convergence of knowledge bases will create a powerful force for innovation. This suggests that statisticians today should turn to computing for knowledge, just as data science turned to mathematics in the past.
<…> data science departments should have faculty who dedicate their careers to advances in data science and who establish partnerships with computer scientists.”
2001: Leo Breiman publishes Statistical Modeling: The Two Cultures:
“There are two cultures in the use of statistical modeling to draw conclusions from data. The first assumes that the data is generated by a given stochastic data model. The second uses algorithmic models and treats the data mechanism as unknown.
The statistical community almost always adheres to the first approach. This commitment has led to irrelevant theory, questionable conclusions, and has prevented statisticians from working on a large number of interesting current problems.
Algorithmic modeling, both in theory and practice, is rapidly developing in fields beyond statistics. It can be used both on large, complex datasets and as a more accurate and informative alternative to modeling on smaller datasets. If our goal as a field is to use data to solve problems, then we need to move away from an exclusive reliance on data models and embrace a more diverse set of tools.”

April 2002. Launch of Data Science Journal, which publishes papers on “data and database management in science and technology.” The journal’s scope includes descriptions of data systems, their online publication, applications, and legal issues. The journal is published by the Committee on Data Science for Science and Technology ( CODATA ) of the International Council for Science (ICSU).
January 2003. The Journal of Data Science was launched :
“By ‘data science,’ we mean virtually everything related to data: collecting it, analyzing it, modeling it… <…> But the most important part is applying it. This journal is dedicated to the application of statistical methods in general <…> The Journal of Data Science will be a platform for all data scientists to present their views and exchange ideas.”
May 2005: Thomas H. Davenport, Don Cohen, and Al Jacobson publish a report, “Competing with Analytics,” from the Babson College Center for Work Skills Research, which describes “the emergence of a new form of competition based on the extensive use of analytics and data, and on fact-based decision making <…>
Instead of competing on traditional factors, companies are beginning to use statistical and quantitative analysis and forecasting as key elements of competitive struggle.”
The research was later published by Davenport in the Harvard Business Review (January 2006) and expanded (with Jeanne J. Harris) into the book Competing on Analytics: The New Science of Winning (March 2007).
Published in Russia under the title “Analytics as a Competitive Advantage. The New Science of Winning.”
September 2005. The National Science Foundation ( NSF ) (USA) publishes “Long-Term Digital Data Collections: Enabling Research and Education in the 21st Century.” One of the report’s recommendations is:
“NSF, working in partnership with collection managers and the community at large, must act to develop and enhance the careers of data scientists and ensure that the research enterprise includes a sufficient number of highly skilled data scientists.”
The report defines data scientists as:
“Information and computer scientists, database and software engineers and programmers, discipline experts, curators and expert annotators, librarians, archivists, and other professionals who are critical to the successful management of digital data collections.”
2007: The Data Science and Data Research Center was established at Fudan University, Shanghai, China.
Here we see a division between the concepts of “data science” and “data science”.
In 2009, two researchers at the Center, Yanyun Zhu and Yun Xiong, published an article, “Introduction to Data Science and Data Science,” which stated:
“Unlike the natural and social sciences, data science and data analytics examine data in cyberspace as the object of their research. This is a new science.” The Center hosts annual symposiums on data science and data science.
“The final report of the study, ‘The Skills, Roles, and Career Structures of Data Scientists and Curators: An Assessment of Current Practices and Future Needs,’ defines data scientists as ‘people who work where research is conducted—or, in the case of data center staff, in close collaboration with data creators—and may be involved in creative search and analysis, enabling others to work with digital data, and developments in database technologies.'”
Here we deliberately do not use the term data scientists, since the definition of the term data scientist has not yet been fully formed [editor’s note].
January 2009. The Interagency Working Group on Digital Data published a report to the Science Committee of the National Science and Technology Council, “Harnessing the Power of Digital Data for Science and Society.” It stated:
“The nation needs to identify disciplines and specialists, and foster the emergence of new disciplines and specialists, competent in solving the complex and dynamic problems of digital data preservation, sustainable access, reuse, and repurposing.
Across many disciplines, a new breed of data science and management experts is emerging, working in computer science, information science, and data science, among other fields. These individuals are key to the current and future success of the scientific enterprise. However, they often go unrecognized for their contributions, and their careers are limited.”
January 2009: Hal Varian, Google’s chief economist, writes in McKinsey Quarterly: “I keep saying that statistics will be the sexiest job in the next ten years.
People think I’m kidding, but who would have thought that computer engineering would become the sexiest profession of the 1990s?
The ability to take data, understand it, process it, extract value from it, visualize it, communicate it—this will be a very important skill in the coming decades <…>
Because now we really do have virtually free, ubiquitous data.
Therefore, an additional deficit factor is the ability to understand this data and extract value from it <…>
I think these skills—the ability to access, understand, and communicate the information gained from data analysis—will be extremely important. Managers must be able to independently access and understand data.”
March 2009. Kirk D. Born and other astrophysicists presented a paper, “Revolutionizing Astronomy Education: Data Science for the Masses,” for the Astro 2010 Decadal Review :
“Teaching the next generation the subtle art of intelligently understanding data is essential for the success of science, communities, projects, agencies, businesses, and the economy. This is true for both specialists (scientists) and non-specialists (everyone else): the public, teachers, students, and workers.
“Specialists must learn and apply new data science research methods to advance our understanding of the universe. Non-specialists need information literacy skills as productive members of the 21st-century workforce, integrating foundational skills for lifelong learning in an increasingly data-driven world.”
May 2009. Mike Driscoll writes in “The Three Sexy Skills of Data Geeks”:
“…with the advent of the data age, those who can model, process, and visualize data—call us statisticians or data geeks—are a hot commodity.” In August 2010, Driscoll will publish a follow-up to ” The Seven Secrets of Successful Data Scientists. “
June 2009. Nathan Yau writes in Rise of the Data Scientist:
“As we’ve all read, Google’s chief economist, Hal Varian, commented in January that the next sexy job in the next 10 years would be statistics. Obviously, I wholeheartedly agree. Heck, I’d go one step further and say they’re sexy now—mentally and physically. However, if you’d continued reading Varian’s interview, you’d have learned that by statistician, he meant someone who can extract insights from large data sets and then present something useful to non-data scientists. <…>
[Ben] Fry <…> argues for the need to create an entirely new field that brings together skills and talents from often disparate fields of knowledge <…>[computer science; mathematics, statistics, and data mining; graphic design; information visualization and human-computer interaction]. And after two years of covering visualization on FlowingData, it seems that collaboration across fields is becoming more common, but more importantly, computational information design is getting closer to reality. We’re seeing data scientists —the people who can do all of this—standing out from the crowd.”
Note the different cases used for the term “Data Scientist.” From 2008 until at least 2011, people continued to be cautious and wrote the term in quotation marks, italics, and all caps, even though the title might contain capital letters.
The article above appears to be a deliberate attempt to standardize capitalization. The original title is “Rise of the Data Scientist,” and the term ” data scientist” is italicized in an attempt to define it. Therefore, a tracing translation is appropriate here to reflect the author’s intent and to distinguish the term. [editor’s note].
June 2009: Troy Sadkowsky creates the data scientists group on LinkedIn as a complement to his website datasceintists.com, which later became datascientists.net.
February 2010. Kenneth Cukier writes in The Economist’s special report, “Data, Data Everywhere” :
“…A new breed of specialist has emerged—the data scientist, who combines the skills of programmer, statistician, and storyteller to extract the gold bars hidden beneath mountains of data.”
June 2010. Mike Loukides writes in the article ” What is Data Science? “:
“Data scientists combine entrepreneurship with patience, a willingness to build data products incrementally, and an ability to explore and iterate on solutions.
They are inherently interdisciplinary. They can tackle all aspects of a problem, from collecting raw data and processing it to formulating conclusions. They can think outside the box, coming up with new ways to approach a problem, or they can work with very broadly defined problems: “Here’s a lot of data, what can you do with it?”
September 2010. Hilary Mason and Chris Wiggins write in the Data Science Taxonomy article :
“…we thought it would be useful to propose one possible taxonomy… of what a Data Scientist does, roughly in chronological order:
“Acquire, clean, explore, model and understand <…> Data science is undoubtedly a mixture of hacking <…> statistics and machine learning… knowledge in mathematics and in the field of data to make the analysis interpretable <…> It requires creative solutions and an open mind in a scientific context.”

September 2010. Drew Conway writes in the article “Venn Diagram for Data Science”:
“…a person must learn a great deal in order to become a fully competent data scientist. Unfortunately, simply listing textbooks and books won’t untangle these knots. Therefore, in an attempt to simplify the discussion and add my own thoughts to the already crowded marketplace of ideas, I present a Venn diagram of data science <…> hacking skills, knowledge of mathematics and statistics, and subject-matter experience.”
May 2011. Pete Warden writes in “Why the term ‘data science’ is flawed but useful”:
There’s no generally accepted definition of what’s within the scope of data science. Is it just a fancy rebranding of statistics? I don’t think so, but I also don’t have a complete definition. I believe the recent abundance of data has given rise to something new in the world, and when I look around, I see people with common traits who don’t fit into traditional categories.
These people typically work outside the narrow specialties that dominate the corporate and institutional world, doing everything from data mining, large-scale data processing, visualization, and writing stories about that data.
They also seem to start by looking at what the data can tell them and then picking out interesting threads, rather than starting with the traditional approach of a scientist who first picks a problem and then finds data to shed light on it.”
May 2011. David Smith writes in “Data Science: What’s in a Name?”:
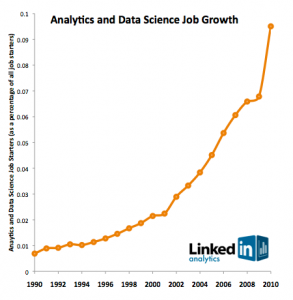
The terms “Data Science” and “Data Scientist” have only been around for a little over a year, but they’ve gained widespread popularity in that time: many companies are now hiring “data scientists,” and entire conferences are being held under the heading “data science.”
But despite its widespread use, some resist the move away from more traditional terms such as “statistician,” “quantitative analyst,” or “data analyst” <…>
…I think “data science” better describes what we actually do: a combination of hacking, data analysis, and problem solving.”
June 2011. Matthew J. Graham, speaking at the workshop “Astrostatistics and Data Mining in Large Astronomical Databases” with a paper titled “The Art of Data Science,” said:
“To thrive in the new, data-rich environment of 21st-century science, we need to develop new skills <…> We need to understand what rules [data] obey, how it is symbolized and communicated, and what its relationship is to physical space and time.”
September 2011. Harlan Harris writes in “Data Science, Moore’s Law, and the Moneyball” :
“Data science is defined as what a ‘Data Scientist’ does.
The work of data scientists has been well described, encompassing all stages: data collection and processing, application of statistics, machine learning, and related methods, interpretation, communication, and visualization of results. Who are data scientists? Perhaps a more fundamental question.
I like the idea that data science is defined by its practitioners, that it’s a career path, not a category of activity. In conversations with people, it seems to me that people who consider themselves data scientists tend to have eclectic career paths that can seem, in some ways, pointless.”
September 2011: Dr. Janurjay Patil writes in “Building Teams in Data Science”:
“In 2008, Jeff Hammerbacher (@hackingdata) and I sat down to share our experiences building data and analytics teams at Facebook and LinkedIn. In many ways, that meeting marked the beginning of data science as a distinct professional specialization: we realized that as our organizations grew, we would both have to decide what to call the people on our teams.
The term “business analyst” proved too narrow. The term “data analyst” was considered for this role, but we felt that title might limit people’s capabilities. After all, many people on our teams had deep engineering expertise.
Research scientist was a reasonable job title at companies like Sun, HP, Xerox, Yahoo, and IBM. However, we felt that most research scientists were working on projects that were futuristic and abstract, and the work was conducted in labs isolated from product development teams.
It can take years for lab research to impact key products, if at all. Instead, our teams focused on developing data applications that could have an immediate and widespread impact on the business. The term that seemed most appropriate was “data scientist”: someone who uses data and science to create something new.”
September 2012: Tom Davenport and Dr. Janurjay Patil publish “Data Scientist: The Sexiest Job of the 21st Century” in Harvard Business Review.